Dr Ahsan Adeel

UK Advanced Research + Invention Agency (ARIA) Creator: Relating Thought to Pyramidal Cells | Director, Conscious Multisensory Integration (CMI) Lab | Fellow, Howard Brain Sciences Foundation | Former Fellow, MIT Synthetic Intelligence & Oxford Computational Neuroscience Lab | Associate Professor of Cellular AI, University of Stirling.
My research focuses on understanding the cellular foundations of human thought, specifically common sense, rationality, and imaginative thinking, key attributes that have made humans one of the most complex and adaptable species.
My latest thesis [Link] explores these fundamental questions, aiming to bridge the gap between the brain and the mind by drawing on recent breakthroughs in cellular neurobiology and computational neuroscience.
But can these cellular mechanisms be replicated in machines? If so, could future AI not only assist humanity, but also elevate it, enhancing our common sense, rationality, and even moral values?
If machines could truly think and imagine like us, what would life look like? Would they redefine personal growth, transform communities, and restructure entire societies? Or is this vision a glimpse of humanity’s next evolutionary step, or merely an unattainable dream?
My most recent publications (2025; 2026) demonstrate how machines (e.g., Transformers) can emulate high-level perceptual and awake imaginative states to preselect relevant information before attention is applied.
My ambitions are fueled by our latest research findings (2024a [Link], 2024b [Link], 2023 [Link], 2022a [Link], 2022b [Link], 2018 [Link]), which offer fundamental insights into the mechanisms of pyramidal Two-Point Neurons (TPNs) in the mammalian neocortex—suggested as the hallmarks of conscious processing [Link], with their dysfunction linked to intellectual learning disabilities [Link]. Latest research also highlights the role of TPNs in mental states, including wakefulness, deep sleep, dreaming, and wakeful thoughts and imagery (Cellular Psychology, W.A. Phillips, Trends in Cognitive Sciences, in press).
My findings support the hypothesis that the processing and learning capabilities of TPNs are essential to the mammalian neocortex and may overcome the computational limitations of current AI. I call this revolution occurring in the sciences of brain, mind, and AI, The Beginning of Real Understanding (BRU), beyond AI.
Check out the latest multi-scale perspective from the flagship €1.2 billion Human Brain Project (HBP) [Link], our work is highlighted as a notable contribution. Additionally, see the recent review by P. Poirazi and her team [Link], which recognizes our research as of 'outstanding interest' in the field of next-generation neuromorphic computing. Our work is also prominently featured in the first book on two-point neurons [Link] by Prof. W.A. Phillips, published by Oxford University Press in March 2023.
Our contribution to this rapidly growing area of cellular neurobiology is encouraging AI experts to incorporate TPNs into state-of-the-art AI models for applications where speed and energy efficiency are crucial. It is also inspiring neurobiologists to explore the fine-tunings required to harness this neurobiological mechanism for solving complex real-world problems.
I am involved in various academic and government projects of significant magnitude, addressing the pressing need for secure, environmentally viable, economical, and resilient AI solutions for the success of emerging technologies in health care, space, underwater, robotics, autonomous cars, and manufacturing. My concept of 5G-IoT enabled MS hearing aids (HAs) was ranked second in the EPSRC’s healthcare technologies grand challenge of frontiers of physical intervention (EP/T021063/1). The team was awarded a £4 million EPSRC transformative healthcare technologies programme grant in 2020. Other projects include, new AI chips for future Mars rovers to go farther, faster, and do more science; biologically plausible models to understand the cellular foundations of conscious experience, anaesthesia, dreaming, hallucinations, autism, and other neurological and developmental disorders.
I hold a B.Eng. in Electrical Engineering, an MSc in Electronics, and a PhD in Cognitive Computing. I have served as a visiting EPSRC/MRC Research Fellow at the University of Stirling and as a Fellow at the MIT Synthetic Intelligence Lab, the Oxford Computational Neuroscience Lab, and the Howard Brain Sciences Foundation. Currently, I am an Associate Professor of Cellular AI and Theoretical Neuroscience at the University of Stirling.
Cognitively-inspired multimodal (MM) hearing-aid:
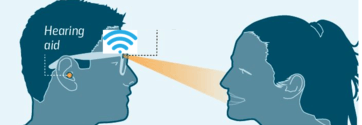 Developing the world’s first biologically plausible multisensory hearing aid that uses video information from lip movements to selectively amplify speech signals heard in noisy environments. It has been shown to be able to remove background noise so well that it can generate speech output in a noisy environment that is as clear as in a noiseless environment. Thus, it is now possible to offer people with impaired hearing intelligent lip-reading hearing aids that will make it far easier for them to perceive speech.
Developing the world’s first biologically plausible multisensory hearing aid that uses video information from lip movements to selectively amplify speech signals heard in noisy environments. It has been shown to be able to remove background noise so well that it can generate speech output in a noisy environment that is as clear as in a noiseless environment. Thus, it is now possible to offer people with impaired hearing intelligent lip-reading hearing aids that will make it far easier for them to perceive speech.
Conscious multisensory integration:
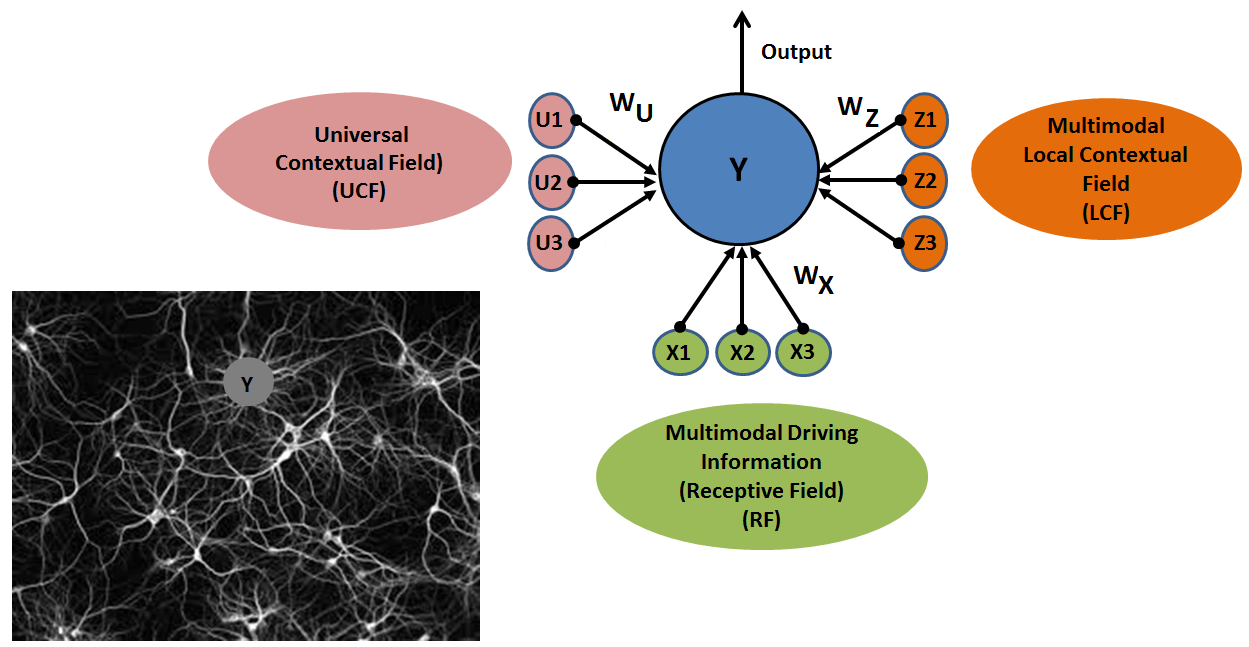 Developing a novel theory on conscious multisensory integration (CMI), which, as opposed to unconditional excitatory and inhibitory activity in existing deep neural networks (DNNs), supports conditional amplification/suppression of feedforward signals, with respect to external environment. The theory sheds light on some crucial neuroscience questions, including: How does the brain integrate the incoming multisensory signals with respect to different external environments? How are the roles of these multisensory signals defined to adhere to the anticipated behavioural-constraint of the environment?
Developing a novel theory on conscious multisensory integration (CMI), which, as opposed to unconditional excitatory and inhibitory activity in existing deep neural networks (DNNs), supports conditional amplification/suppression of feedforward signals, with respect to external environment. The theory sheds light on some crucial neuroscience questions, including: How does the brain integrate the incoming multisensory signals with respect to different external environments? How are the roles of these multisensory signals defined to adhere to the anticipated behavioural-constraint of the environment?
Understanding information decomposition in conscious multisensory integration:
 This work aims to further understand the information decomposition in conscious multisensory integration. Specifically, we are quantifying the suppression and attenuation of multisensory (AV) signals in terms of four basic arithmetic operators (addition, subtraction, multiplication and division) and their various forms. The aim is to analyze how the information is decomposed into components unique to each other having multiway mutual/shared information in a CMI model.
This work aims to further understand the information decomposition in conscious multisensory integration. Specifically, we are quantifying the suppression and attenuation of multisensory (AV) signals in terms of four basic arithmetic operators (addition, subtraction, multiplication and division) and their various forms. The aim is to analyze how the information is decomposed into components unique to each other having multiway mutual/shared information in a CMI model.
Computational modelling of biological audio-visual processing in Alzheimer's and Parkinson's diseases using conscious multisensory integration: Sensory impairments have an enormous impact on our lives and are closely linked to cognitive functioning. Neurodegenerative processes in AD and PD affect the structure and functioning of neurons, resulting in altered neuronal activity. For example, patients with AD suffer from sensory impairment and lack the ability to channelize awareness. However, the cellular and neuronal circuit mechanisms underlying this disruption are elusive. Therefore, it is important to understand how multisensory integration changes in AD/PD, and why patients fail to guide their actions. This project aims to further extend the existing preliminary CMI research to understand how the roles of audio and visual cues change with respect to the outside world in patients with neurodegenerative diseases (e.g. AD/PD).
Neurodegenerative processes in AD and PD affect the structure and functioning of neurons, resulting in altered neuronal activity. For example, patients with AD suffer from sensory impairment and lack the ability to channelize awareness. However, the cellular and neuronal circuit mechanisms underlying this disruption are elusive. Therefore, it is important to understand how multisensory integration changes in AD/PD, and why patients fail to guide their actions. This project aims to further extend the existing preliminary CMI research to understand how the roles of audio and visual cues change with respect to the outside world in patients with neurodegenerative diseases (e.g. AD/PD).
Explainable artificial intelligence:
 Undoubtedly, existing AI and deep learning systems exhibit impressive performance and effectuate tasks that are normally performed by humans. Yet, these end-to-end multimodal AI models operate at the network level and fail to justify reasoning with limited generalization and real-time analytics; thereby, restricting their application in areas where outcomes have an impact on humans. On the other hand, humans can extrapolate from a small number of examples, and are quick to learn and generalize lessons learned in one situation to instances that occur in different contexts. In this work, we are using CMI and advances in information decomposition to address the aforementioned problems and develop XAI algorithms.
Undoubtedly, existing AI and deep learning systems exhibit impressive performance and effectuate tasks that are normally performed by humans. Yet, these end-to-end multimodal AI models operate at the network level and fail to justify reasoning with limited generalization and real-time analytics; thereby, restricting their application in areas where outcomes have an impact on humans. On the other hand, humans can extrapolate from a small number of examples, and are quick to learn and generalize lessons learned in one situation to instances that occur in different contexts. In this work, we are using CMI and advances in information decomposition to address the aforementioned problems and develop XAI algorithms.
Low-power neuromorphic chips:
 This research work aims to develop energy efficient (low-power) neuromorphic chips and IoT sensors by exploiting the controlled firing property of the CMI theory. The CMI model inherently leverages the complementary strengths of incoming multisensory signals with respect to the outside environment and anticipated behaviour.
This research work aims to develop energy efficient (low-power) neuromorphic chips and IoT sensors by exploiting the controlled firing property of the CMI theory. The CMI model inherently leverages the complementary strengths of incoming multisensory signals with respect to the outside environment and anticipated behaviour.
EPSRC funded project: Towards flexible electronic hearing aid (HA) implementations
 In collaboration with the University of Manchester , we are creating an audio-visual (AV) HA platform based upon flexible electronics, which are now being made as “temporary tattoos” for improved discreteness and social acceptability. .
In collaboration with the University of Manchester , we are creating an audio-visual (AV) HA platform based upon flexible electronics, which are now being made as “temporary tattoos” for improved discreteness and social acceptability. .
EPSRC funded project: On-chip big data processing
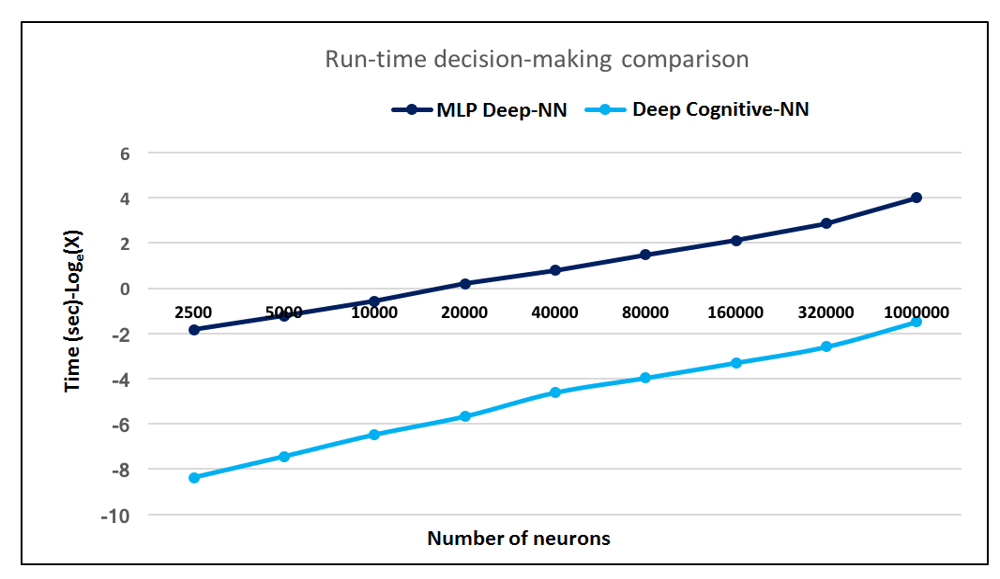
 In collaboration with the University of Manchester, Alpha Data, and ENU , we are implementing deep cognitive neural network (DCNN) features for autonomous, privacy-preserving transfer learning (TL). Preliminary work has demonstrated such DCNN architectures are capable of highly energy-efficient, on-chip implementations, with fast decision-making, excellent generalization, and large gains per-operation scaling with deep structures for large scale processing. For very large-scale simulations, comprising 1M neurons and 2.5B synapses, have demonstrated up to 300X faster decision-making compared to DNNs. .
In collaboration with the University of Manchester, Alpha Data, and ENU , we are implementing deep cognitive neural network (DCNN) features for autonomous, privacy-preserving transfer learning (TL). Preliminary work has demonstrated such DCNN architectures are capable of highly energy-efficient, on-chip implementations, with fast decision-making, excellent generalization, and large gains per-operation scaling with deep structures for large scale processing. For very large-scale simulations, comprising 1M neurons and 2.5B synapses, have demonstrated up to 300X faster decision-making compared to DNNs. .
EPSRC funded project: Privacy-preserving, multimodal (MM) lip-reading (LR)
In collaboration with the University of Glasgow , we are exploring the groundbreaking technology of ambient radio frequency (RF), for lip-reading.
EPSRC funded project: deep transfer learning (TL)
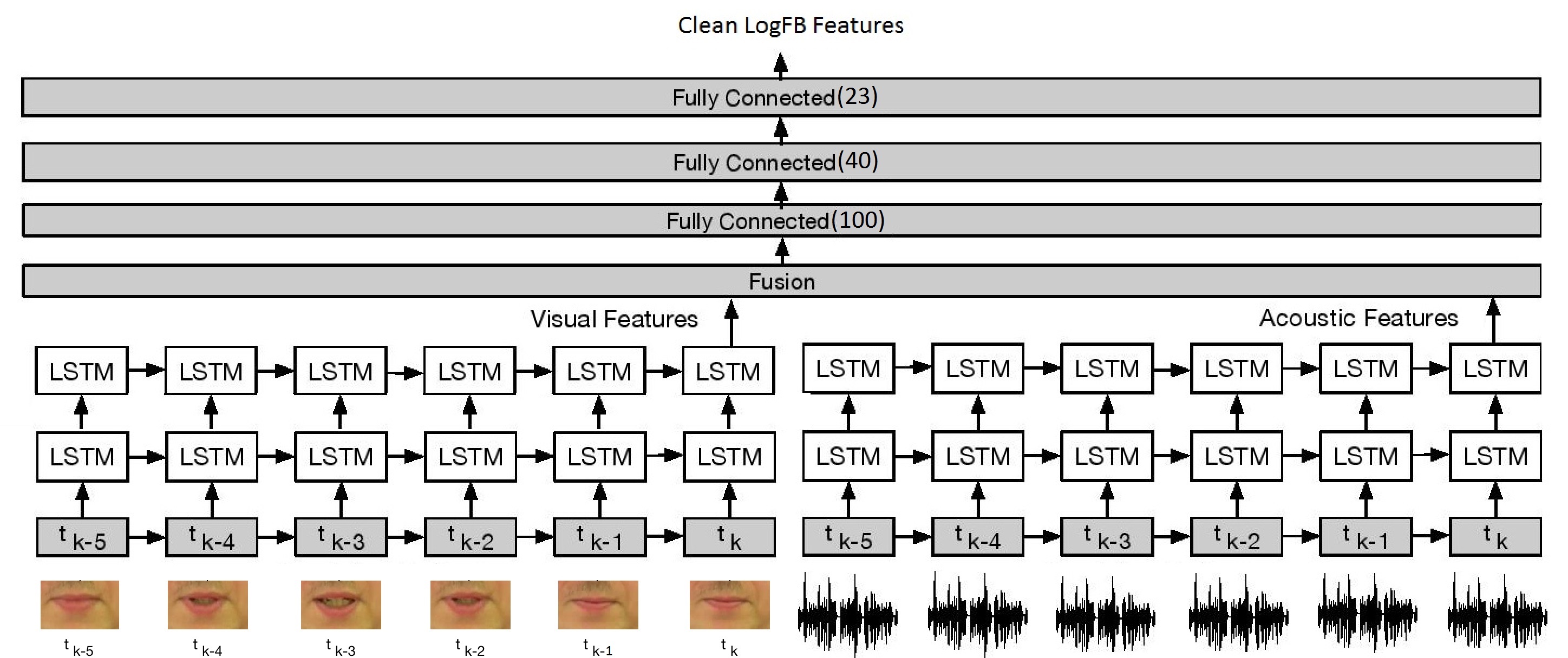 In collaboration with the University of Edinburgh and ENU , we are developing deep TL based generalized audio-visual (AV) speech enhancement (SE) algorithms. We are further building our innovative, context-aware DNN based AV mask estimation and SE filtering models, including through top-down models of speech, inspired by human cognition and evolution.
In collaboration with the University of Edinburgh and ENU , we are developing deep TL based generalized audio-visual (AV) speech enhancement (SE) algorithms. We are further building our innovative, context-aware DNN based AV mask estimation and SE filtering models, including through top-down models of speech, inspired by human cognition and evolution.
Hearing Loss Testing:
 In collaboration with Princeton University, New Jersey and the National University of Computer and Emerging Sciences, we are developing an automated cost-effective pre-screening test to predict hearing loss at an early stage. The device can potentially offer a second opinion to audiologists and can also be utilized in developing countries or rural areas where there is a lack of well-educated audiologists.
In collaboration with Princeton University, New Jersey and the National University of Computer and Emerging Sciences, we are developing an automated cost-effective pre-screening test to predict hearing loss at an early stage. The device can potentially offer a second opinion to audiologists and can also be utilized in developing countries or rural areas where there is a lack of well-educated audiologists.
Dementia Sensitive Personalized Environment Planner App:
 With the support of Dementia Services Development Centre at the University of Stirling, we are empowering people with cognitive impairments (e.g. dementia, autism, major depressive disorder) to proactively choose their personalized surrounding environment using a 5G small cell technology driven proactive environment planner app.
With the support of Dementia Services Development Centre at the University of Stirling, we are empowering people with cognitive impairments (e.g. dementia, autism, major depressive disorder) to proactively choose their personalized surrounding environment using a 5G small cell technology driven proactive environment planner app.
Embedded Security for IoT:
 Developing a pioneering technology that is capable of providing on- chip low power intrusion detection and encryption in embedded and multi-core computing systems. These represent a cost-effective alternative, and a comparatively superior approach to state-of-the-art ARM (Arm Cortex-A, Cortex- M23, and Cortex-M33) processors - TrustZone http://arm.com/products/processors/technologies/trustzone and Intel's work (https://software.intel.com/en-us/articles/intel-virtualization-technology-for-directed- io-vt-d-enhancing-intel-platforms-for-efficient-virtualization-of-io-devices).
Developing a pioneering technology that is capable of providing on- chip low power intrusion detection and encryption in embedded and multi-core computing systems. These represent a cost-effective alternative, and a comparatively superior approach to state-of-the-art ARM (Arm Cortex-A, Cortex- M23, and Cortex-M33) processors - TrustZone http://arm.com/products/processors/technologies/trustzone and Intel's work (https://software.intel.com/en-us/articles/intel-virtualization-technology-for-directed- io-vt-d-enhancing-intel-platforms-for-efficient-virtualization-of-io-devices).
IoT sensors: In collaboration with the National University of Science and Technology, we are developing a new IoT standard, DeepNode. DeepNode stands as a major enabler for future smart cities, healthcare and industrial monitoring, and environmental/earth (remote) sensing. The DeepNodeWAN is capable of processing a large amount of sensitive data quickly with low power consumption and high throughput, complying with the intelligent secure RRM and diverse communication requirements in massive real-time communication domains.
AV Ear Defenders - SE Application in Navy and Military:
 Collaboration with the University of Texas at Dallas to explore and exploit the potential of our develop AV speech enhancement technology in the US Navy (for people controlling aircraft carriers deck operations), US military (for officers not wearing earplugs), air traffic control towers (to improve communication and reduce the risk of accidents), and cargo trains (to address driver distraction).
Collaboration with the University of Texas at Dallas to explore and exploit the potential of our develop AV speech enhancement technology in the US Navy (for people controlling aircraft carriers deck operations), US military (for officers not wearing earplugs), air traffic control towers (to improve communication and reduce the risk of accidents), and cargo trains (to address driver distraction).
Disaster Management:
 Collaboration with the Tianjin University of Technology to explore the application of our disruptive multimodal speech processing technology in extremely noisy environments e.g. in situations where ear defenders are worn, such as emergency and disaster response and battlefield environments.
Collaboration with the Tianjin University of Technology to explore the application of our disruptive multimodal speech processing technology in extremely noisy environments e.g. in situations where ear defenders are worn, such as emergency and disaster response and battlefield environments.
Asthma:
 Collaboration with the Edinburgh Medical School to understand the role of exogenous sex steroid hormones in female patients with asthma. Specifically, we are finding the correlation between the use of hormonal contraceptives and asthma exacerbations in reproductive age females.
Collaboration with the Edinburgh Medical School to understand the role of exogenous sex steroid hormones in female patients with asthma. Specifically, we are finding the correlation between the use of hormonal contraceptives and asthma exacerbations in reproductive age females.
Multiphase Flow Meter Calibration:
 A novel deep learning driven time-series predictive and optimization model for uncertainty growth prediction and calibration intervals optimization. The technology addresses the limitations of state-of-the-art mathematical/statistical uncertainty growth and calibration intervals predictive methods such as limited modelling assumptions, limited learning, lack of ability to deal with non-linear complex behaviours, and poor scalability. State-of-the-art literature reveals that it is difficult to solve the calibration optimization equation in closed form.
A novel deep learning driven time-series predictive and optimization model for uncertainty growth prediction and calibration intervals optimization. The technology addresses the limitations of state-of-the-art mathematical/statistical uncertainty growth and calibration intervals predictive methods such as limited modelling assumptions, limited learning, lack of ability to deal with non-linear complex behaviours, and poor scalability. State-of-the-art literature reveals that it is difficult to solve the calibration optimization equation in closed form.
Collision Free Wi-Fi routing:
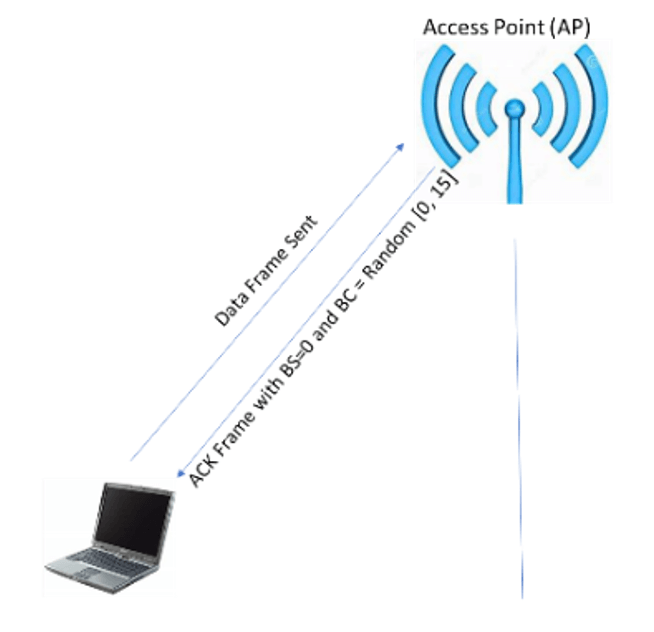 A novel deep learning driven collision free Wi-Fi routing algorithm to enable larger number of nodes in smart cities. Social and digital infrastructure of a IoT-based smart city could be boosted by deploying high-density public WiFi. Indeed, WiFi is a key to smart cities. Existing Wi-Fi devices operate following the 802.11 standards with the aim to fairly use the channel that the devices share. However, the throughput performance of the existing Wi-Fi networks suffers from high packet loss and supports very limited number of nodes with low datarate.
A novel deep learning driven collision free Wi-Fi routing algorithm to enable larger number of nodes in smart cities. Social and digital infrastructure of a IoT-based smart city could be boosted by deploying high-density public WiFi. Indeed, WiFi is a key to smart cities. Existing Wi-Fi devices operate following the 802.11 standards with the aim to fairly use the channel that the devices share. However, the throughput performance of the existing Wi-Fi networks suffers from high packet loss and supports very limited number of nodes with low datarate.
Acute general hospital admission: Collaboration with the Dementia Services Development Centre at the University of Stirling, we are helping policymakers to explore predictors of good/bad outcome following acute general hospital admission for people with cognitive impairment.
Keynotes/Research Visits (2017 onward)
Local organizing committee chair, IEEE World Congress on Computational Intelligence (IEEE WCCI) 2020, 19 - 24th July, 2020, Glasgow (UK)
Keynote speaker at the National Pattern Recognition Laboratory, Chinese Academy of Sciences, Beijing, Oct 19th 2019. Talk on Conscious Multisensory Integration
Invited talk on AV speech processing, School of Computing Sciences, University of East Anglia, January, 2019
Invited talk on multisensory integration and its application to low-power neuromorphic chips, School of Computer Science, University of Manchester, Feb 2019
Invited talk on Accurate Model Of The Retinal Response, at the Computational Neuroscience and Cognitive Robotics Centre, Nottingham Trent University, March 2019
Invited visit to UTD for exploitation of our develop AV speech enhancement technology in the US Navy, Jan 2018
Invited visit to MIT for the development of a novel highly energy efficient, Deep Cognitive Neural Network (DCNN) for cognitive IoT devices and neuromorphic chips, Dec 2017
Invited visit to Harvard for possible collaboration on skin based flexible electronics development, Dec 2017
Invited speaker at SICSA Conference on Big Data Science Innovations: Prospects in Smart Cities, Media and Governance, Nov, 2016
Invited talk on contextual audio-visual processing, Computing Science and Maths Seminars, University of Stirling, January, 2019
Keynote on AI application to geological disaster management, Harbin Institute of Technology, Harbin, China, British Council-China initiative, supported by Newton Fund Researcher Links, April 2017
Keynote speaker, Suzhou University of Science and Technology, China, April 2018
Keynote invitation, Fifth International Conference on Biosignals, Images and Instrumentation ICBSII 2019, SSN College of Engineering, Chennai, Tamil Nadu, 14- 15th March 2019
Keynote invitation, 2nd World Congress on Mechanical and Mechatronics Engineering (WCMME-2019), April 15-16, 2019 at Dubai, UAE
GCU guest speaker, RiSE 2nd Conference, School of Engineering and Built Environment, Glasgow Caledonian University, June 2018
Keynote, Workshop on Big Data-driven Condition-monitoring and Signal-processing with Applications to the Oil & Gas Industry, Glasgow Caledonian University, June 2017
Talk at the Medical Research Council Network Meeting for Hearing-Impaired Listeners, Stirling, May, 2018
Invited visit to Edinburgh School of Art, ESRC Charter house Project, Oct 2017
Invited visit to Edinburgh medical school, meeting on OPCRD Sex Hormones & Asthma, Nov, 2017
Invited talk, lip-reading driven hearing-aid technology, Stockholm University, Sweden, Sept, 2017
Invited talk at the University of Oxford, AI based automated liver cancer diagnosis, July, 2017
Talk at the Medical Research Council Network Meeting for Hearing-Impaired Listeners, MRC Cardiff, July 2017
Invited visit to the the Scottish Dementia Research Consortium Event, Dundee, 20th April, 2017
Workshop chair, IEEE Symposium Series on Computational Intelligence (SSCI), SSCI 2017), Dec 2017
Invited visit, Dementia Design App, University of Stirling, External Advisory Board Meeting, Sept 2017
Invited visit, GCRF, SDG6 (Water and Sanitation) Stirling Meeting, September. 2017
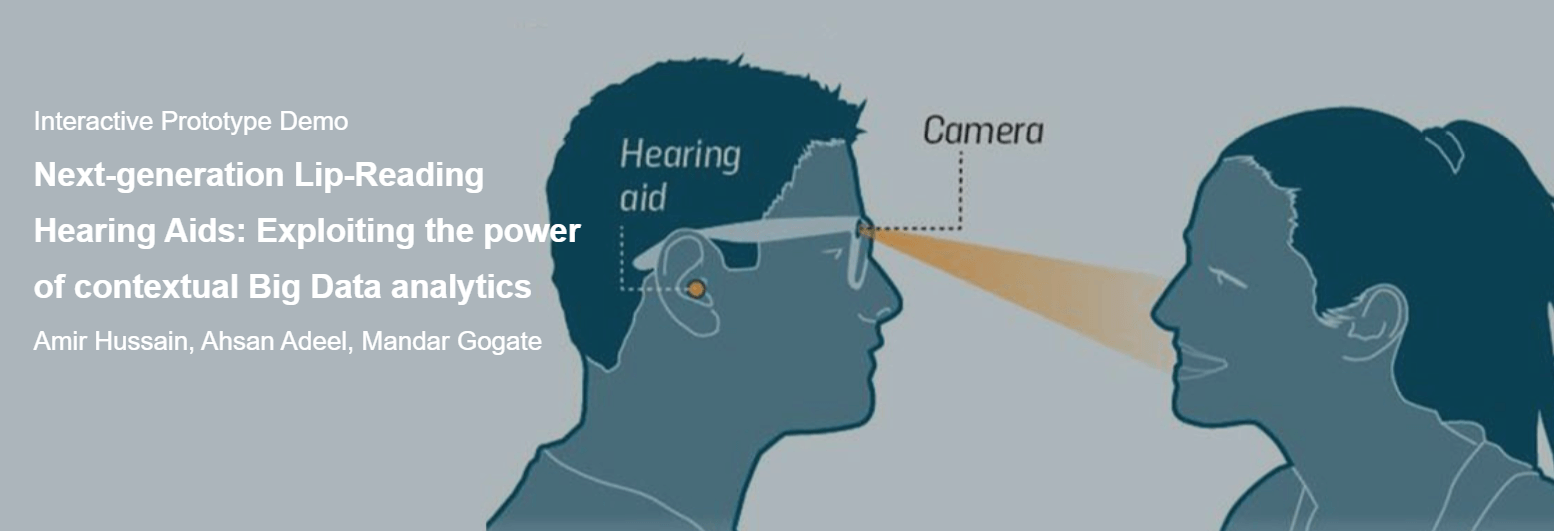
Interactive Prototype Demo Next-generation Lip-Reading Hearing Aids: Exploiting the power of contextual Big Data analytics
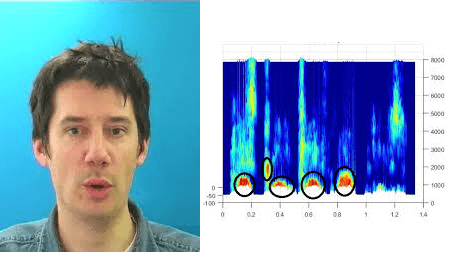
- CochleaNet: A Robust Language-independent Audio-Visual Model for Speech Enhancement https://cochleanet.github.io/:
 Noisy situations cause huge problems for suffers of hearing loss as hearing aids often make the signal more audible but do not always restore the intelligibility. In noisy settings, humans routinely exploit the audio-visual (AV) nature of the speech to selectively suppress the background noise and to focus on the target speaker. In this paper, we present a causal, language, noise and speaker independent AV deep neural network (DNN) architecture for speech enhancement (SE). The model exploits the noisy acoustic cues and noise robust visual cues to focus on the desired speaker and improve the speech intelligibility. To evaluate the proposed SE framework a first of its kind AV binaural speech corpus, called ASPIRE, is recorded in real noisy environments including cafeteria and restaurant. We demonstrate superior performance of our approach in terms of objective measures and subjective listening tests over the state-of-the-art SE approaches as well as recent DNN based SE models. In addition, our work challenges a popular belief that a scarcity of multi-language large vocabulary AV corpus and wide variety of noises is a major bottleneck to build a robust language, speaker and noise independent SE systems. We show that a model trained on synthetic mixture of Grid corpus (with 33 speakers and a small English vocabulary) and ChiME 3 Noises (consisting of only bus, pedestrian, cafeteria, and street noises) generalise well not only on large vocabulary corpora but also on completely unrelated languages (such as Mandarin), wide variety of speakers and noises.
Noisy situations cause huge problems for suffers of hearing loss as hearing aids often make the signal more audible but do not always restore the intelligibility. In noisy settings, humans routinely exploit the audio-visual (AV) nature of the speech to selectively suppress the background noise and to focus on the target speaker. In this paper, we present a causal, language, noise and speaker independent AV deep neural network (DNN) architecture for speech enhancement (SE). The model exploits the noisy acoustic cues and noise robust visual cues to focus on the desired speaker and improve the speech intelligibility. To evaluate the proposed SE framework a first of its kind AV binaural speech corpus, called ASPIRE, is recorded in real noisy environments including cafeteria and restaurant. We demonstrate superior performance of our approach in terms of objective measures and subjective listening tests over the state-of-the-art SE approaches as well as recent DNN based SE models. In addition, our work challenges a popular belief that a scarcity of multi-language large vocabulary AV corpus and wide variety of noises is a major bottleneck to build a robust language, speaker and noise independent SE systems. We show that a model trained on synthetic mixture of Grid corpus (with 33 speakers and a small English vocabulary) and ChiME 3 Noises (consisting of only bus, pedestrian, cafeteria, and street noises) generalise well not only on large vocabulary corpora but also on completely unrelated languages (such as Mandarin), wide variety of speakers and noises.
- CHiME3 AV Corpus https://cogbid.github.io/chime3av/#about:
 This new publicly available dataset is based on the benchmark audio-visual GRID corpus, which was originally developed by our project partners at Sheffield for speech perception and automatic speech recognition. The new dataset contains a range of joint audiovisual vectors, in the form of 2D-DCT visual features, and the equivalent audio log-filterbank vector. All visual vectors were extracted by tracking and cropping the lip region of a range of Grid videos (1000 videos from five speakers, giving a total of 5000 videos), and then transforming the region with 2D-DCT. The audio vector was extracted by windowing the audio signal, and transforming each frame into a log-filterbank vector. The visual signal was then interpolated to match the audio, and a number of large datasets were created, with the frames shuffled randomly to prevent bias, and with different pairings, including multiple visual frames to estimate a single audio frame (from one visual to one audio pairings, to 28 visual to one audio pairings). This dataset will enable researchers to evaluate how well audio speech can be estimated using visual information only. Specifically, the application of novel speech enhancement algorithms (including those based on advanced machine learning), can be used to evaluate the potential of exploiting visual cues for speech enhancement.
This new publicly available dataset is based on the benchmark audio-visual GRID corpus, which was originally developed by our project partners at Sheffield for speech perception and automatic speech recognition. The new dataset contains a range of joint audiovisual vectors, in the form of 2D-DCT visual features, and the equivalent audio log-filterbank vector. All visual vectors were extracted by tracking and cropping the lip region of a range of Grid videos (1000 videos from five speakers, giving a total of 5000 videos), and then transforming the region with 2D-DCT. The audio vector was extracted by windowing the audio signal, and transforming each frame into a log-filterbank vector. The visual signal was then interpolated to match the audio, and a number of large datasets were created, with the frames shuffled randomly to prevent bias, and with different pairings, including multiple visual frames to estimate a single audio frame (from one visual to one audio pairings, to 28 visual to one audio pairings). This dataset will enable researchers to evaluate how well audio speech can be estimated using visual information only. Specifically, the application of novel speech enhancement algorithms (including those based on advanced machine learning), can be used to evaluate the potential of exploiting visual cues for speech enhancement.
- ASPIRE dataset https://cogbid.github.io/ASPIRE/#about:
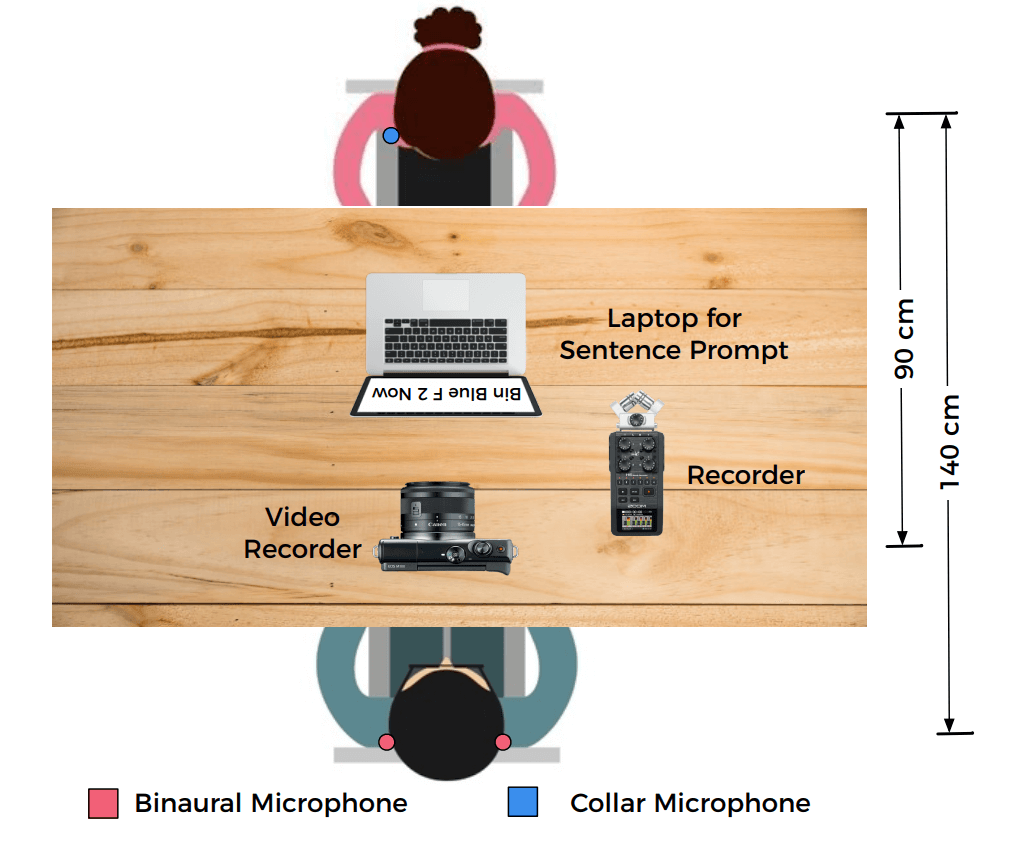 ASPIRE is a a first of its kind, audiovisual speech corpus recorded in real noisy environment (such as cafe, restaurants) which can be used to support reliable evaluation of multi- modal Speech Filtering technologies. This dataset follows the same sentence format as the audiovisual Grid corpus.
ASPIRE is a a first of its kind, audiovisual speech corpus recorded in real noisy environment (such as cafe, restaurants) which can be used to support reliable evaluation of multi- modal Speech Filtering technologies. This dataset follows the same sentence format as the audiovisual Grid corpus.
- First audio-visual (AV) speech in real-noise challenge.
 A detailed description of the AV challenge, a novel real noisy AV corpus (ASPIRE), benchmark speech enhancement task, and baseline performance results are outlined in [Link]. The latter are based on training a deep neural architecture on a synthetic mixture of Grid corpus and ChiME3 noises (consisting of bus, pedestrian, cafe, and street noises) and testing on the ASPIRE corpus. Subjective evaluations of five different speech enhancement algorithms (including SEAGN, spectrum subtraction (SS) , log-minimum mean-square error (LMMSE), audio-only CochleaNet, and AV CochleaNet) are presented as baseline results. The aim of the multi-modal challenge is to provide a timely opportunity for comprehensive evaluation of novel AV speech enhancement algorithms, using our new benchmark, real-noisy AV corpus and specified performance metrics. This will promote AV speech processing research globally, stimulate new ground-breaking multi-modal approaches, and attract interest from companies, academics and researchers working in AV speech technologies and applications. We encourage participants (through a challenge website sign-up) from both the speech and hearing research communities, to benefit from their complementary approaches to AV speech in noise processing.
A detailed description of the AV challenge, a novel real noisy AV corpus (ASPIRE), benchmark speech enhancement task, and baseline performance results are outlined in [Link]. The latter are based on training a deep neural architecture on a synthetic mixture of Grid corpus and ChiME3 noises (consisting of bus, pedestrian, cafe, and street noises) and testing on the ASPIRE corpus. Subjective evaluations of five different speech enhancement algorithms (including SEAGN, spectrum subtraction (SS) , log-minimum mean-square error (LMMSE), audio-only CochleaNet, and AV CochleaNet) are presented as baseline results. The aim of the multi-modal challenge is to provide a timely opportunity for comprehensive evaluation of novel AV speech enhancement algorithms, using our new benchmark, real-noisy AV corpus and specified performance metrics. This will promote AV speech processing research globally, stimulate new ground-breaking multi-modal approaches, and attract interest from companies, academics and researchers working in AV speech technologies and applications. We encourage participants (through a challenge website sign-up) from both the speech and hearing research communities, to benefit from their complementary approaches to AV speech in noise processing.
Selected Publications (2017-2020)
-
- Howard, N., Chouikhi, N., Adeel, A., Dial, K., Howard, A., & Hussain, A. (2020). BrainOS: A Novel Artificial Brain-Alike Automatic Machine Learning Framework. Frontiers in Computational Neuroscience, 14, 16.
- Ieracitano, C., Adeel, A., Morabito, F. C., & Hussain, A. (2020). A novel statistical analysis and autoencoder driven intelligent intrusion detection approach. Neurocomputing, 387, 51-62.
- Newton Howard, Ahsan Adeel, Mandar Gogate, Amir Hussain, A Novel Highly Energy-Efficient, Deep Cognitive Neural Network, 2019 (patent Appl. No. 62/588,210) Link
- Adeel, Ahsan, Mandar Gogate, and Amir Hussain. "Contextual Deep Learning-based Audio-Visual Switching for Speech Enhancement in Real-world Environments." Information Fusion (2019). Link
- Ahsan Adeel, Mandar Gogate, Amir Hussain, William M. Whitmer, Lip-Reading Driven Deep Learning Approach for Speech Enhancement, IEEE Transactions on Emerging Topics in Computational Intelligence, 2019 Link
- Interactive Prototype Demo: Next-generation Lip-Reading Hearing Aids: Exploiting the power of contextual Big Data analytics. Link
- Gogate, Mandar, Kia Dashtipour, Ahsan Adeel, and Amir Hussain, ASPIRE dataset, 2019. Link
- Ahsan Adeel, Mandar Gogate, Amir Hussain, CHiME3 AV Corpus, 2019. Link
- Ahsan Adeel, “Role of Awareness and Universal Context in a Spiking Conscious Neural Network: A New Perspective and Future Directions”, Frontiers in Neuroscience, 2019 (Submitted, Pre-print available online). Link
- Gogate, Mandar, Kia Dashtipour, Ahsan Adeel, and Amir Hussain. "CochleaNet: A Robust Language-independent Audio-Visual Model for Speech Enhancement." arXiv preprint arXiv:1909.10407 (2019). Link
- Gogate, Mandar, Kia Dashtipour, Ahsan Adeel, and Amir Hussain, AV Speech Enhancement Challenge using a Real Noisy Corpus, Arxiv, 2019. Link
- Cosimo Ieracitano, Ahsan Adeel, Francesco C Morabito, Amir Hussain, A Statistical Analysis and Autoencoder Driven Intelligent Intrusion Detection, Neurocomputing, 2019 (accepted for publication).
- Shibli Nisar, Muhammad Tariq, Ahsan Adeel, Mandar Gogate, Amir Hussain, Cognitively Inspired Feature Extraction and Speech Recognition for Automated Hearing Loss Testing, Cognitive Computation, 2019. Link
- Ozturk, Metin, Mandar Gogate, Oluwakayode Onireti, Ahsan Adeel, Amir Hussain, and Muhammad A. Imran. "A novel deep learning driven low-cost mobility prediction approach for 5G cellular networks: The case of the Control/Data Separation Architecture (CDSA)." Neurocomputing, 2019. Link
- Ahsan Adeel, et al. "A Survey on the Role of Wireless Sensor Networks and IoT in Disaster Management." Geological Disaster Monitoring Based on Sensor Networks, Springer, Singapore, 2019. Link
- Ahsan Adeel, Jawad Ahmed, Amir Hussain, Real-Time Lightweight Chaotic Encryption for 5G IoT Enabled Lip-Reading Driven Hearing-Aid, Cognitive Computation, 2018 (accepted for publication/available online) Link
- Ahsan Adeel, Hadi Larijani, and Ali Ahmadinia. "Random neural network based cognitive engines for adaptive modulation and coding in LTE downlink systems." Computers & Electrical Engineering, 2017.
- Ahsan Adeel, Hadi Larijani, and Ali Ahmadinia. "Random neural network based novel decision making framework for optimized and autonomous power control in LTE uplink system." Elsevier Physical Communication.
- Ahsan Adeel, Hadi Larijani, and Ali Ahmadinia. "Resource management and inter-cell-interference coordination in lte uplink system using random neural network and optimization." IEEE Access Cognitive Networking, (published).
- Ahsan Adeel, H. Larijani, A. Ahmadinia, Impact of Learning Algorithms on Random Neural Network based Optimization for LTE-UL Systems, Network Protocols, Special Issue on Software Defined and Cognitive Networks.
- Cosimo Ieracitano, Ahsan Adeel, Mandar Gogate, Kia Dashtipour, Francesco Carlo Morabito, Hadi Larijani, Ali Raza, Amir Hussain, Statistical Analysis Driven Optimized Deep Learning System for Intrusion Detection, BICS 2018
- Kia Dashtipour, Mandar Gogate, Ahsan Adeel, Cosimo Ieracitano, Hadi Larijani, Amir Hussain, Exploiting Deep Learning for Persian Sentiment Analysis, BICS 2018 Imane Guellil, Ahsan Adeel, SentiALG: Automated Corpus Annotation for Algerian Sentiment Analysis, BICS 2018
- Fengling Jiang, Bin Kong, Ahsan Adeel, Saliency Detection via Bidirectional Absorbing Markov Chain, BICS 2018
- Gogate, Mandar, Ahsan Adeel, Ricard Marxer, Jon Barker, and Amir Hussain. "DNN driven Speaker Independent Audio-Visual Mask Estimation for Speech Separation, INTERSPEECH, 2018
- GUELLIL, Imane, Ahsan Adeel,"Arabizi sentiment analysis based on transliteration and automatic corpus annotation." 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, pp. 335-341. 2018.
- Ahsan Adeel, Mandar Gogate, Amir Hussain, Towards Next-Generation Lip-Reading Driven Hearing-Aids: A preliminary Prototype Demo, CHAT, INTERSPEECH, 2017
- Hussain, A., Barker, J., Marxer, R., Adeel, A., Whitmer, W., Watt, R., & Derleth, P. Towards Multi-modal Hearing Aid Design and Evaluation in Realistic Audio-Visual Settings: Challenges and Opportunities, CHAT, INTERSPEECH, 2017
- Mandar Gogate, Ahsan Adeel and Amir Hussain, A novel brain-inspired compression-based optimised multimodal fusion for emotion recognition, IEEE Symposium Series on Computational Intelligence, SSCI 2017
- Kia Dashtipour, Mandar Gogate, Ahsan Adeel, Amir Hussain, Persian Named Entity Recognition, IEEE ICCIC, 2017
- Mandar Gogate, Ahsan Adeel and Amir Hussain, Deep Learning Driven Multimodal Fusion For Automated Deception Detection, IEEE Symposium Series on Computational Intelligence, SSCI 2017